5. moldrug without receptor#
One of the strengths of moldrug is the ability to optimize on the chemical space based on docking results. However it could also be used to optimize some QSAR function when the information of the receptor is not available. Some previous of this application where show here.
5.1. Imports and creating working directory#
from moldrug import utils
from rdkit import Chem
from rdkit.Chem import Lipinski, Draw
import multiprocessing as mp
import shutil, os, gzip, requests, tempfile
# Remember to change to your vina executable
# If you define as a path, it must be absolute
vina_executable = '/Users/klimt/GIT/docking/bin/vina'
# Defining the wd and change directory
wd = 'wd'
os.mkdir(wd)
os.chdir(wd)
5.2. Getting the CReM data base#
url = "http://www.qsar4u.com/files/cremdb/replacements02_sc2.db.gz"
r = requests.get(url, allow_redirects=True)
crem_dbgz_path = 'crem.db.gz'
crem_db_path = 'crem.db'
open(crem_dbgz_path, 'wb').write(r.content)
with gzip.open(crem_dbgz_path, 'rb') as f_in:
with open(crem_db_path, 'wb') as f_out:
shutil.copyfileobj(f_in, f_out)
5.3. Define the function#
Let’s assume that our QSAR model give us that the best molecules are those ones that have more hydrogen bonds acceptor and donors. Because MolDrug minimize we must use the negative of this number.
def QSAR_model_cost(Individual:utils.Individual) -> utils.Individual:
"""Simple cost function
Parameters
----------
Individual : utils.Individual
An initialize Individual
Returns
-------
utils.Individual
The individual with cost sum of HBA and HBD with negative sign
"""
NumHAcceptors = Lipinski.NumHAcceptors(Individual.mol)
NumHDonors = Lipinski.NumHDonors(Individual.mol)
model = NumHAcceptors + NumHDonors
Individual.cost = -model
return Individual
5.4. Set MolDrug run#
The next code is a duplication for the implementation of QSAR_model_cost fitness function.
Is written in this way due to some possible problems that might arise because the execution of multiprocessing inside GA on an interactive Python like IPython-Notebook.
For that we will create the python script and to be able to executed it inside the NoteBook.
script = """
from rdkit.Chem import Lipinski
from rdkit import Chem
from moldrug import utils
import multiprocessing as mp
def QSAR_model_cost(Individual):
NumHAcceptors = Lipinski.NumHAcceptors(Individual.mol)
NumHDonors = Lipinski.NumHDonors(Individual.mol)
model = NumHAcceptors + NumHDonors
Individual.cost = -model
return Individual
if __name__ == "__main__":
ga = utils.GA(
Chem.MolFromSmiles('CCCC'),
crem_db_path='crem.db',
maxiter=10,
popsize=50,
costfunc=QSAR_model_cost,
mutate_crem_kwargs={
'ncores': mp.cpu_count()
},
costfunc_kwargs={},
randomseed=1234,)
ga(12)
ga.pickle(title='ga', compress = True)
"""
with open('script.py', 'w') as f:
f.write(script)
! python script.py
Creating the first population with 50 members:
100%|███████████████████████████████████████████| 50/50 [00:01<00:00, 25.55it/s]
Initial Population: Best Individual: Individual(idx = 15, smiles = CC(N)C(=N)NO, cost = -7)
Accepted rate: 50 / 50
Evaluating generation 1 / 10:
100%|███████████████████████████████████████████| 46/46 [00:01<00:00, 23.01it/s]
Generation 1: Best Individual: Individual(idx = 15, smiles = CC(N)C(=N)NO, cost = -7).
Accepted rate: 27 / 46
Evaluating generation 2 / 10:
100%|███████████████████████████████████████████| 48/48 [00:02<00:00, 23.54it/s]
Generation 2: Best Individual: Individual(idx = 140, smiles = COc1nc(N)nc(N)c1N=O, cost = -9).
Accepted rate: 16 / 48
Evaluating generation 3 / 10:
100%|███████████████████████████████████████████| 47/47 [00:02<00:00, 21.33it/s]
Generation 3: Best Individual: Individual(idx = 153, smiles = OCC1OC(O)C(O)C(O)C1O, cost = -11).
Accepted rate: 15 / 47
Evaluating generation 4 / 10:
100%|███████████████████████████████████████████| 47/47 [00:02<00:00, 20.84it/s]
Generation 4: Best Individual: Individual(idx = 153, smiles = OCC1OC(O)C(O)C(O)C1O, cost = -11).
Accepted rate: 16 / 47
Evaluating generation 5 / 10:
100%|███████████████████████████████████████████| 48/48 [00:02<00:00, 21.09it/s]
Generation 5: Best Individual: Individual(idx = 153, smiles = OCC1OC(O)C(O)C(O)C1O, cost = -11).
Accepted rate: 12 / 48
Evaluating generation 6 / 10:
100%|███████████████████████████████████████████| 49/49 [00:02<00:00, 21.81it/s]
Generation 6: Best Individual: Individual(idx = 297, smiles = OCC(O)C(O)C(O)C(O)CO, cost = -12).
Accepted rate: 16 / 49
Evaluating generation 7 / 10:
100%|███████████████████████████████████████████| 49/49 [00:02<00:00, 19.99it/s]
Generation 7: Best Individual: Individual(idx = 297, smiles = OCC(O)C(O)C(O)C(O)CO, cost = -12).
Accepted rate: 18 / 49
Evaluating generation 8 / 10:
100%|███████████████████████████████████████████| 49/49 [00:02<00:00, 22.01it/s]
Generation 8: Best Individual: Individual(idx = 297, smiles = OCC(O)C(O)C(O)C(O)CO, cost = -12).
Accepted rate: 17 / 49
Evaluating generation 9 / 10:
100%|███████████████████████████████████████████| 46/46 [00:02<00:00, 19.40it/s]
Generation 9: Best Individual: Individual(idx = 297, smiles = OCC(O)C(O)C(O)C(O)CO, cost = -12).
Accepted rate: 13 / 46
Evaluating generation 10 / 10:
100%|███████████████████████████████████████████| 48/48 [00:02<00:00, 18.39it/s]
Generation 10: Best Individual: Individual(idx = 297, smiles = OCC(O)C(O)C(O)C(O)CO, cost = -12).
Accepted rate: 13 / 48
=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+
The simulation finished successfully after 10 generations witha population of 50 individuals. A total number of 527 Individuals were seen during the simulation.
Initial Individual: Individual(idx = 0, smiles = CCCC, cost = 0)
Final Individual: Individual(idx = 297, smiles = OCC(O)C(O)C(O)C(O)CO, cost = -12)
The cost function dropped in 12 units.
=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+
Total time (10 generations): 1173.43 (s).
Finished at Thu Jun 13 15:03:33 2024.
ga = utils.decompress_pickle('ga.pbz2')
Draw.MolsToGridImage([ga.InitIndividual.mol, ga.pop[0].mol])
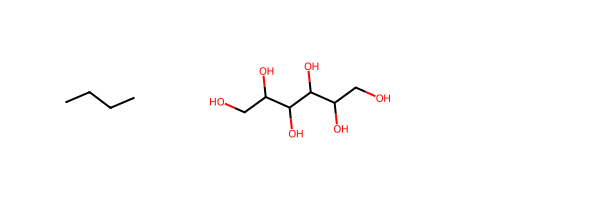
As you can see, this simulation is really good: On every single carbon atom it is bound, at least, one HBD and/or HBA!
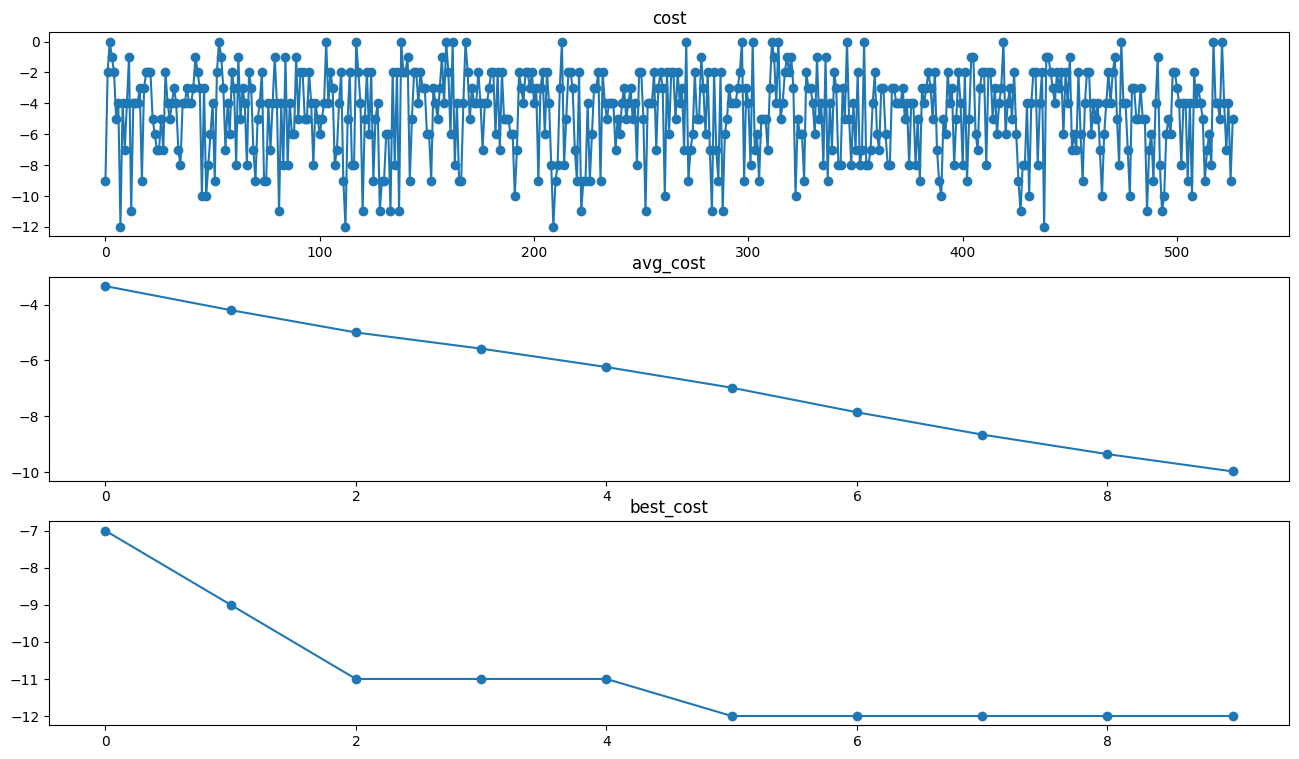
import matplotlib.pyplot as plt
fig, ax = plt.subplots(nrows=3, figsize = (16,9))
ax[0].plot([individual.cost for individual in ga.SawIndividuals], '-o')
ax[0].set(title = 'cost')
ax[1].plot([cost for cost in ga.avg_cost], '-o')
ax[1].set(title = 'avg_cost')
ax[2].plot([cost for cost in ga.best_cost], '-o')
ax[2].set(title = 'best_cost')
[Text(0.5, 1.0, 'best_cost')]